Tradycyjne metody monitoringu przestały być wystarczające w dobie złożonych systemów - wymagane jest bardziej wnikliwe zrozumienie systemów oraz przyśpieszanie rozwiązywania incydentów.
Sama implementacja systemów obserwowalnych i ich utrzymanie rodzi nowe problemy. Zewnętrzne systemy służą do obserwowania aplikacji; kwestionowanie w celu poznania wewnętrznej pracy systemu i stanu systemu.
Jeżeli mamy możliwość pozyskania informacji na temat stanu aplikacji w każdym jej aspekcie nawet z którymi byliśmy nie zaznajomieni jeszcze jakiś czas temu, których nie przewidzieliśmy - a przyszły nam one dopiero teraz i mamy możliwość zweryfikowania tychże danych. Oznacza to, że wskaźnik Observability systemu jest wysoki.
Stale musimy usprawniać proces zwiększania wskaźnika Observability; dzięki wysokiemu Observability możemy wypatrywać niecodziennych/podejrzanych wzorców i zachowań; pozwala na analizę interakcji użytkownika z systemem; dzięki Observability mamy wgląd w dynamikę komunikacji między mikro serwisami/kontenerami; taka analiza powinna być standardowym elementem pracy programistów (development life-cycle). Observability daje możliwość wglądu w zachowanie systemu, dzięki tym informacją deweloperzy mogą poprawiać niezawodność/wydajność systemu; analiza logów, metryk, trace’ów pozwala na zidentyfikowanie bottleneck’ów wydajnościowych;
Kluczowe koncepty:
- Root cause analysis
- Highly observable system (has intricate details/critical insights)
- Realtime monitoring/alerting
- resource utilization
- error rates
- Synthetic Journeys
- performance metrics
- deviations from normal patterns
- APM (Application Performance Monitoring)
- application dependencies,
- Distributed tracing - złożone systemy gdzie pojedynczy request oddziałuje na wiele mikro serwisów w różnych data centers - taki trace ma swój ID
- Telemetry Instrumentations (Open Telemetry Standard) event wysyłany do central location (tracking user journey; troubleshooting errors)
- Site Reliability Engineering (SRE)
- feature flagging
- incident analysis
- blue-green deployment
- chaos engineering; “pytania które zostaną postawione bez wcześniejszej wiedzy”
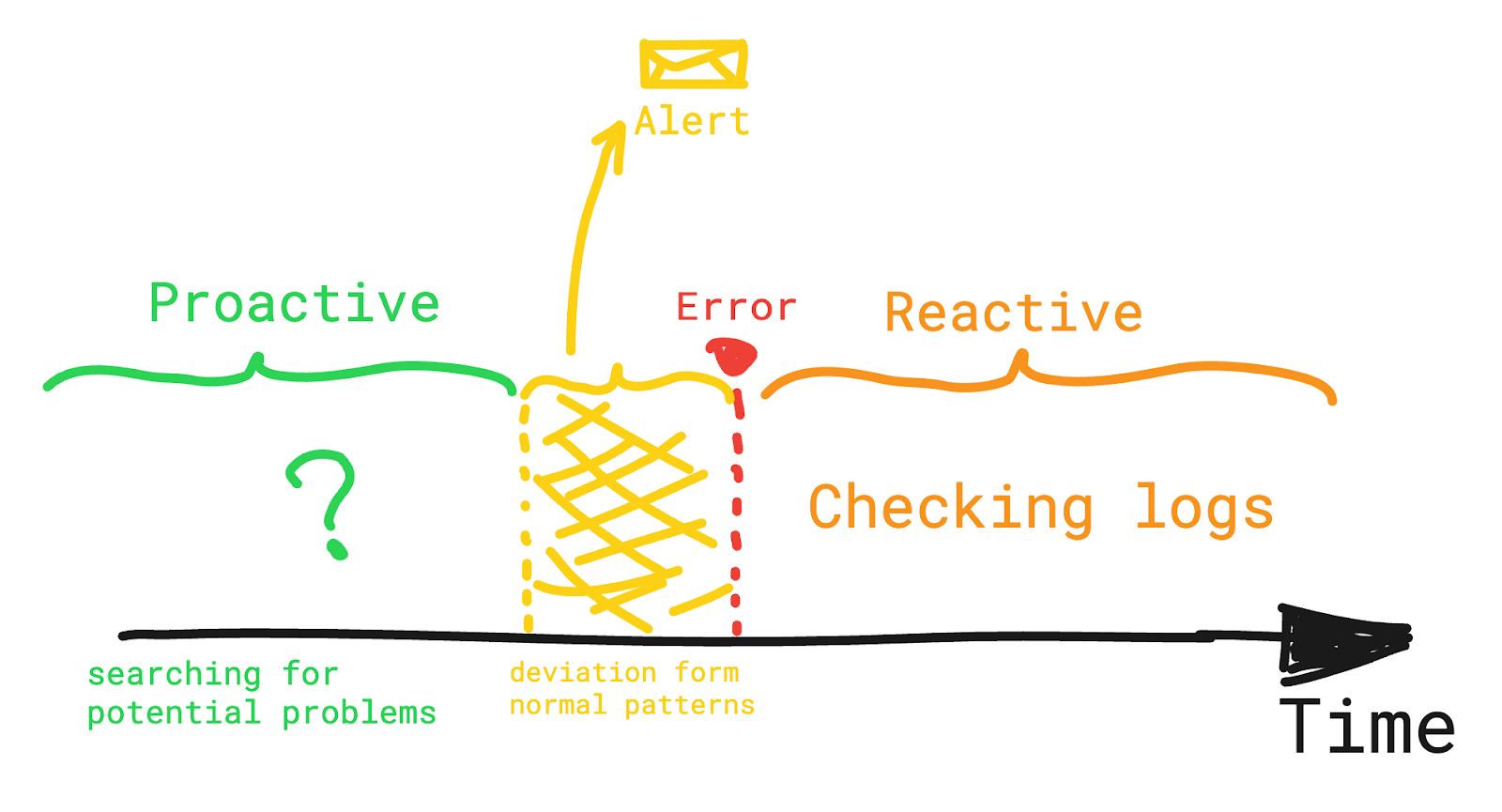
- alert ➡️ wartość progowa predefiniowanej metryki została przekroczona; remediations (środki zaradcze)
- podejście reaktywne: zidentyfikowanie i rozwiązanie problemu po tym jak wystąpi
- podejście proaktywne
Alert musi mieć dane dot. powodu jego wystąpienia (moje doświadczenie: miejsce wystąpienia, dane kontekstowe - zasobu którego dotyczy).
Tradycyjny monitoring i dashboardy polegają na wiedzy Seniora (dependency on human expertise) - czyli metodologia (tradycyjny monitoring) polegająca na objawach aniżeli na actual Root Cause - to nie może być dłużej stosowane gdy złożoność i skala jest duża; “Information to debug issues in details”, “ask open questions”, “trace the system to find real cause of problems (deeply hidden)”; organizacja nie polega na wiedzy eksperta i na subiektywnym zgadywaniu, a prowadzi do bardziej obiektywnej analizy; Złożone interakcje między systemami rozproszonymi; metrics, events, logs, traces, telemetry data - unforeseen issues. Szybkie rozwiązanie problemu to ograniczenie down-time; identify & solve potential issue before they affect users - w przeciwieństwie do reagowania na problem; Problemy z Observability: przechowywanie tych danych, przesyłanie tych danych po sieci; zmiana sposobu myślenia z re na pro; observability kosztuje; security & privacy;
Brak komentarzy:
Prześlij komentarz